效率神器之Alfred Workflow
效率神器之Alfred Workflow
一个Go的Alfred Workflow简单封装库: https://github.com/scbizu/alfredV3
简介
生活在Mac上的工作者肯定对效率神器 Alfred 不会陌生, 免费版的APP提供了比Spotlight更加友好以及强大的文件搜索和Quick Web Search功能,令人眼前一亮。本文就不对这些功能的操作和演示作过多说明了。本文将要介绍的是Alfred Workflow对开发者及其友好的另一个功能: Workflow.
Workflow
Alfred Workflow通过在弹出框中执行输入的命令,从而给出可以操作的各项输出。从这个角度可以认为是Terminal的简化版,让用户更快地通过Alfred提供的脚本或是自定义的脚本来获取自己想要的信息,然后对这些信息(可能是某个网址,某个复杂计算的结果)进行相应的操作(进行跳转或只是复制到剪贴板)。
适用
Workflow对那些每天都进行重复工作的电脑使用者来说应该是加速工作的不二之选了。可以把每天必须要进行的操作编写成脚本,亦或是对自己经常使用的APP(包括锁屏/待机等一些系统操作)设置热键。
正片
越来越多实用的workflow被 awesome alfred 收录,但是一些不常用的workflow还是得自己动手开发,作为一头对造轮子( ~~作死~~ )充满着渴望的猿来说,如果连一个workflow都写不出来的话 那真的是太不酷了。
于是,我开始探索GitHub,试图找到一些关于alfred workflow的开源代码 和 README。然而,作为一只gopher,这个时候不能扔掉自己的信仰.倒是也有几个用Go写的脚手架,但是 似乎都是基于Alfred2的。Alfred2 和 Alfred3 的区别最大的就是文件解析方式吧。从3开始,Alfred Workflow 开始支持json作为result的解析方式。 这对打算用Go来重写的我来说,无疑是一个极好的消息,由于之前跟某国企对接的时候,接口要用SOAP来交互,所以就必须用到XML,这时候被Go的 一个很奇怪的issue (有点久远 但类似这个)折磨过,虽然最后还是折腾出了 这货 ,但是,过程异常痛苦。所以 就打算以后只要有后退的余地,就坚决不用XML数据格式来encode数据。
折腾经历
在粗略阅读了 Alfred Workflow的Document 之后,就开始动手改造之前的cmd app,但是屡屡失败。
- 失败#01:
参考了 一个GitHub上高Star的一个workflow ,于是就觉得workflow的交互应该就是 调用一个二进制程序 然后把output输出到弹出的面板上。在workflow里按照Document和参考demo编写好Shell后 输入关键字 然后什么都没有发生。。。。
- 失败#02:
又仔细阅读了一下Document里面关于 Script Filter 的描述之后,开始意识到面板中输出的需要经过decode.看了一遍Document里提到的属性后,嗯,果然,还是什么都不知道。但还是先把能用的属性封装成了一个能看的结构体。
- 看到希望的失败#03:
这时候开始处理一些Demo Workflow的bug,偶然发现了一个类似浏览器Console的Workflow Debug Console,这个东西还真是对开发者友好啊。
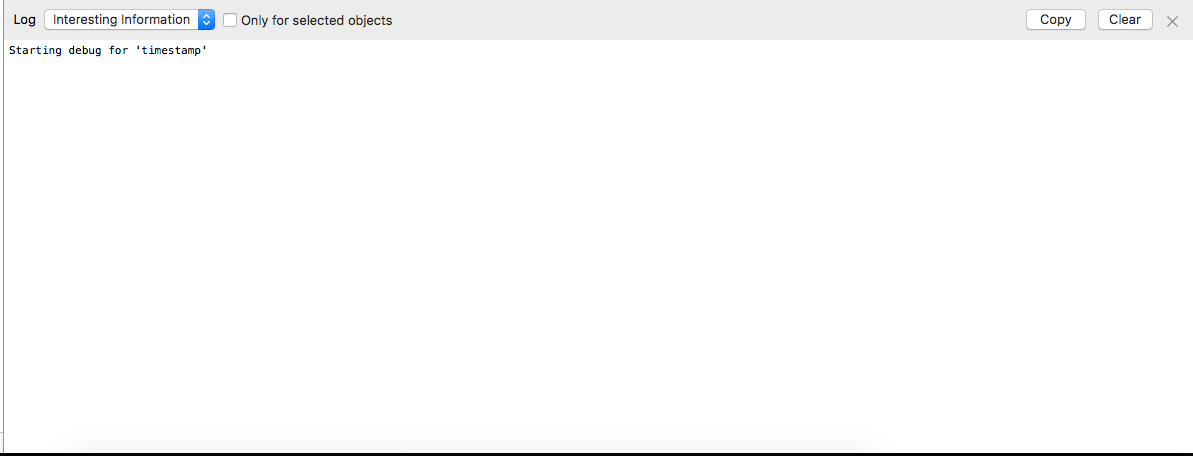
根据这个来快速定位Bug还是高效的XD
把CMD APP转换成更方便的Alfred Workflow
VIM玩家请无视我
写着Workflow的时候 就在想需要一个通用的方法把自己之前的cmd app 无缝迁到Workflow,于是写了一个很Low的方法:
上面代码的大概意思就是 就是把output放在面板中的一行中显示出来,并标记它是可以有效的且是可以被选中复制的(copy字段的内容就是该行被 ⌘+C 之后可以被粘贴到剪贴板的内容)。这大概就可以勉强符合自己的预期效果了。
编译并运行
得益于Go方便的二进制编译,在 go build 之后把生成的二进制文件扔到你创建的Workflow目录下, 注意这是非常关键的一步, 找不到自己新建的Workflow的目录的话,可以在Workflow 目录右击你的Workflow来查看:
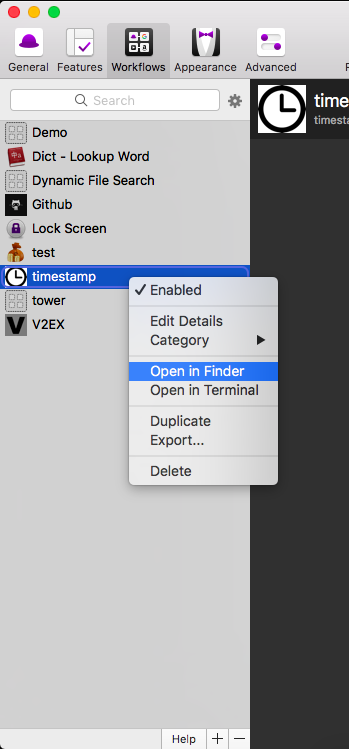
然后把二进制程序扔进去就好了。当然,是不是通过二进制程序触发还得看Shell怎么写,像Python这样的脚本语言 就只要把 xxx.py 扔进去就可以了,也就是说Workflow Script Filter Shell环境的 当前目录 就是 这个Workflow在Finder里面的目录。(当然还是觉得 Open in Terminal 比较方便)。
文件缓存
说起Go的文件缓存,还是偏爱 bolt 。于是就用bolt作为了Workflow的文件缓存。参考着前辈们的demo改造了一下缓存,先来大概说一下Workflow里是怎么玩文件缓存的:
从代码中很容易就可以看出来 在找到cache目录之后 文件缓存怎么玩全看开发者自己的操作了。找cache目录其实是个比较麻烦的过程,Alfred在安装时会默认设置 alfred_workflow_cache 的值,从系统变量里是可以获取的到的,但是Alfred安装时也可以不指定这个变量 这就会导致这个变量是个空值。所以,就只能通过workflow下的 info.plist 来手动拼接Cache目录。
至于实现那就很简单了,我指定了缓存过期的时间,在缓存过期之前,搜索的key都会被映射至其对应的value.为了方便,我给expire的值单独开了一个bucket,这样就可以实现同key不同value的Set/Get了。
Cache可以用在需要运算时间 并且值也不会经常改变的场景。通过 StroreData 缓存映射结果集:
//Cache defines cache object
type Cache struct {
Expire int64
Res []string
Input string
}
然后 通过 FetchData 用Input来获取之前计算过的Result。
关于demo的截图(时间戳转换小工具 TS)
- 两个模式(时间戳转换成多种格式的日期格式/特定日期格式转换成时间戳):
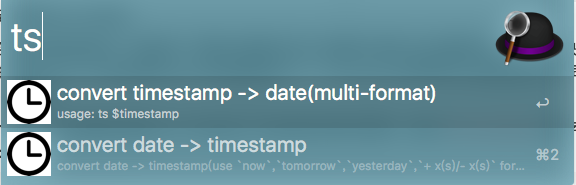
- 特定日期格式转换成时间戳:
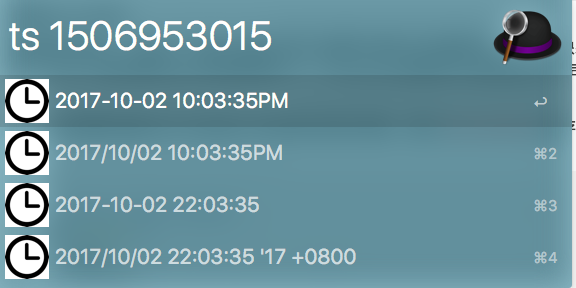
- 时间戳转换成多种格式的日期格式:

结语
关于Workflow 其实还是有很多不少地方值得折腾 看上文看得出来 这边基本是关于Script Filter的折腾日记 关于其他的Action 我还是会继续折腾: ) 也会陆续更新在这个repo里面 希望它可以帮到更多人提高工作效率 减少重复工作带来的困扰。
以上。