tape x bee : 我对智能体任务的编排方式
Contents
前文提要
新的故事
我们在用 tape x topic 构建了业务知识库之后,业务开始有了更长(ye)远(xin)的计划1: 我们是不是可以使用企业内部知识库的知识,来让智能体完成一些需要原本大量人力投入的工作 ? 这些工作的投入产出比(ROI)相对低 , 也可能会有一定的风险,属于 better-to-have 的工作类型,但是这些工作往往能引导业务在稳住基本盘的情况下,得出一些更有创新型的点子,并且可以由 AI 来辅助完成。
举个电商平台实际场景的栗子 🌰:
电商平台为了提高爆品率,往往会设置类似「闪购」这种类似促销活动,这种商品池子往往通过 marketing 同事复杂的分析来最后得出一批各个品类最有机会的商品,这个过程需要一大堆用户数据,商品数据,BI 数据从而导致最后的结果会 fallback 到在往期的商品池子上稍微修修改改就上线,从而导致转化率并没有起色。
一些启发
disclaimer: 其实我没有看过 openclaw 和 hermes 的代码,以下是 AI 总结的 🤡
openclaw 虽然框架本身比较臃肿,但是,它对于指导智能体完成某个 long-run 的任务(在 openclaw 中,它叫做 detached task )还是可以作为前车之鉴:
它把任务分为了:
- Background Task (shell script/forked-process 等): 可以 dry-run 的任务,one-shot 的任务, run 完就停,这些往往会有明确的交付产物
- Context Task: 这类任务没有具体的交付产物,在执行完之后结果会被注入 Context ,之后的 Context 都会带上这个任务的结果
- Cron: 定时任务,由内部的 Scheduler 统一调控
- LLM Task: 交给内置的大模型来运行这个任务
- Managed Task Flow: 由多个子任务结合起来的 task workflow,可以任意编排组合以上的任务类型,有点 DAG 的意思。
再来看 hermes agent 的设计,hermes 对比 openclaw 对于 Job 类型的设计更加 built-in ,所以描述也更加自然:
- Cron: 支持从 chat / cli 发起的一种定时任务 (new_model_session),当然也支持 one shot 。比较亮眼的是,这些 cron 可以 attach back 到对应的 chat session 上。也可以在 chat session 上管理这些 cron 的状态 (依托于 hermes 自己的 daemon scheduler gateway,实现上也没啥难度)。
- SubAgent: 支持在主任务上创建可以允许并发执行的子任务。(我对这个设计打个问号: 因为我们内部的 agentic-rag 过程,也会从 main agent session 分裂出 sub agent session, 这个过程是很自然的,完全不用特意指定这一定要是个 需要 sub agent 去做 concurrent work 的任务,agent 本身会根据 workload 自己来拆的,做好一些 harness 的设置就好了,比如 concurrent slot 是多少,在需要分裂的时候怎么组织 main 和 各个 sub 的状态,这些都可以重用标准分布式系统的范式,在一些小 workload 的情况下,其实并不需要一定要subs,毕竟按照现在各个 coding agent 的设计,多一个session处理任务就多一份 backgrond context window 的💰)。
我们来进行一个总结,并且快进到发表暴论环节:
- Cron 和 one-shot Job 原本的定义并没有推翻,人类世界的原始需求也没有发生改变: 我们需要 agent 遵循人类世界已经有的需求处理关于「怎么处理周期性重复任务」/ 「怎么处理 SOP 已经很完善的任务」。
- 换言之,这不就是套了层大模型外壳的 CI (Continues Integration) 吗 ?想想现在我们对于 CI 的方案是怎么样的:
- GitHub Action
- Serverless Function (aws Lambada , Cloudflare Workers , …)
- 或者基于已有的容器平台的自建服务: Kubernetes Job/Cron , Nomad Job , 以及各种 work scheduler
- 为什么换到 agent 时代,我们就需要重新发明一套所谓「用于给 agent 任务调度的调度器」?如果我们按照上一篇中 tape.systems 关于「重用基础设施」的偏好继续 move on , 把 agent 看成一个更智能的「人」,他应该就会高效使用工具,复用人类世界已经有了的基础设施。
- 根据 tape.systems 的 single session 抽象,如果我们把 Job / Cron 进行更近一步的设计,就可以得到一个雏形:
- 基于 Turn 结构的 Job 定义
- 有明确 boundary 的一串连续 Turn
- 有明确的 goal 作为 task summary 可以做 embedding index
- 咦 ?这不就是一个可以允许自动增长的 topic 吗 ?🧐
全新的 topic – bee
export type ProfileTopic<
TProfile extends TopicProfile,
TExtra extends object = {},
> = TopicRecord & {
profile: TProfile;
} & TExtra;
export type BeeProfileTopic = ProfileTopic<"bee">;
想到这里,我就基于上一篇提到的 topic 概念之上加上了 profile 的概念,用来描述不同的 topic kind,比如上一篇中的 topic 就可以用一种 (default) chat kind 来描述,这次新增一种 kind 来表示 Job/Cron (我叫它 bee ,因为这很像某种形式上的工蜂,为了整个 Cluster 一直在忙)。
这个阶段做了好多系统框架层面的重构工作,Codex GPT-5.4 写的代码工程上的架构远比我想的要难以维护,这里就不多吐槽了,我在 X 和 TG Channel 上已经吐槽了够多了,也进行了很多的自我反思,这里就不多展开了,就再推荐一下 FrostMing 在重构 bub 时的感悟吧,如果你也在为维护大片 AI Slop 而困扰,读完你应该也会有点感悟。
方案设计
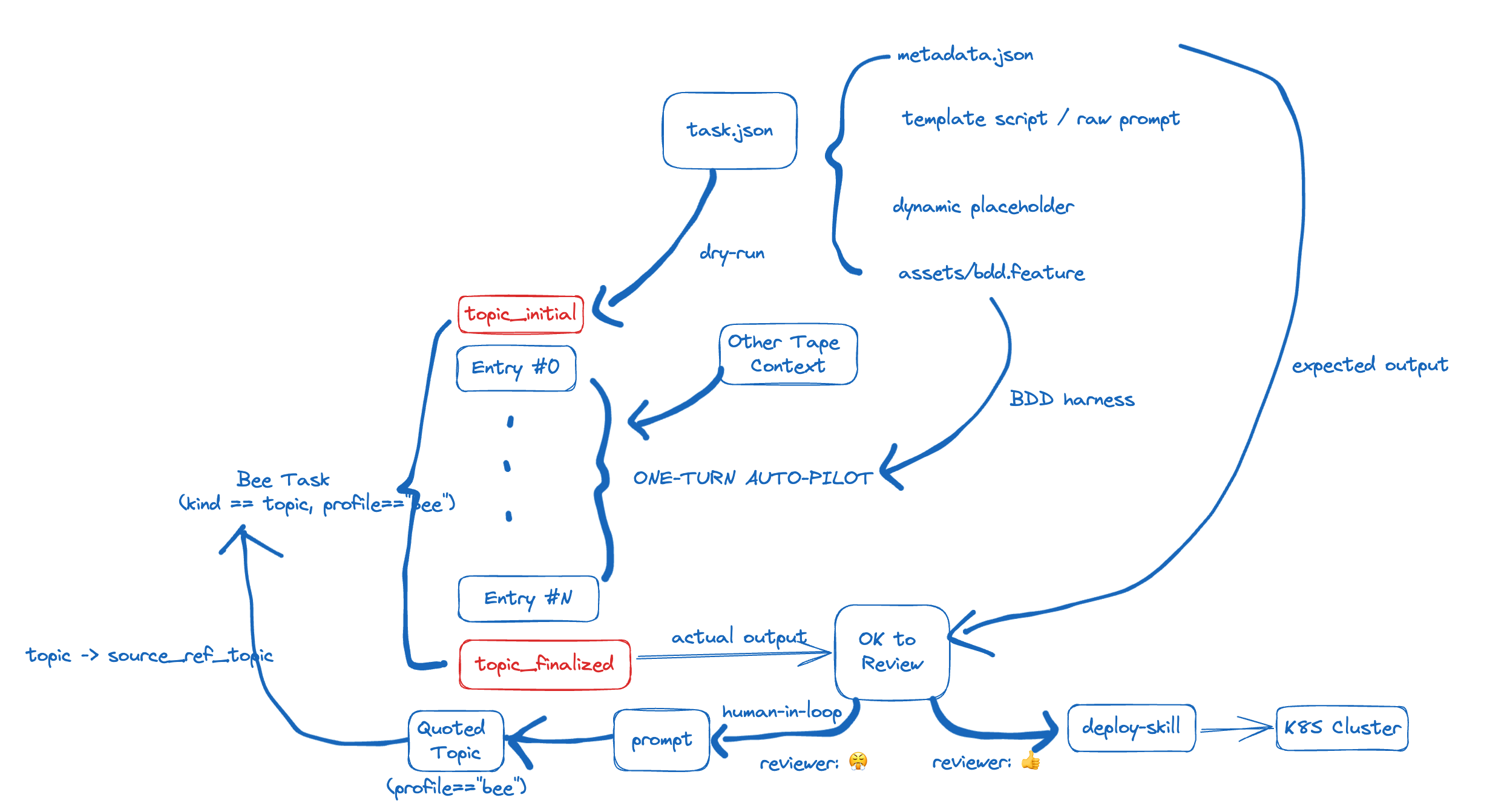
我把 Bee 拆成了这几个模块:
- 模版描述文件:
- 模版需要人为维护,我们的目的是帮助业务方更好得向 AGENT 描述需求,当然,这些模版的维护者往往是业务侧的开发者们。这个模板的设计符合 Codex SKILL spec,让 GPT 可以把它作为 SKILL 来理解我们业务侧的需求:
- assets/metadata.json2: 用 DAG3 的形式来描述整个工作流,这样不管在 UI 和 agent 框架的代码结构上都会更加清晰,也为后面可以扩展的编排功能留了个口子。
- assets/config.toml: 搭配着 SKILL.md 使用,SKILL.md 中的一些需要隐私的配置可以写在配置文件里面,在文档里面维护对它的引用就可以,因为 SKILL.md 的文档会直接暴露在平台上。
- SKILL.md: 这是一份偏业务需求的说明文档,由人为编写或者由 agent 根据内置的 writing-bee-skills 来自动根据需求文档转译,模版中的 SKILL.md 更多的是一个通用的占位符,业务可以后续根据自己实际情况通过 UI 来调整,也就是说,这是绑定在每个 bee 身上的行为规范。
- assets/*.features: 我们通过 BDD 来约束 AGENT 是否可以认为某个 DAG Node 完成;在我的实践中发现 agent 会通过一些 trick 来欺骗我任务已经完成,实际是因为想偷懒而不想等待某些异步操作返回。所以,我就开始加 BDD 来约束他的行为。我只能说,这比在 SKILL.md 的某些 soft prompt 效果好的多。
其实,前几版的实现中,我还会在 scripts/example.ts 给它几个 example 来实现某些业务功能,但是,我发现反而适得其反了,agent 因为太参考我的实现,而把这个 SKILL 当作是一个正常的SKILL 来执行,但是,实际上,我们需要 agent 把 bee skill 当作 meta-skill 来看待,它需要自己通过代码实现和调试完整某个业务目标。于是,我把这些 example code 移到了一个 using-bee-template 的 skill 中,并且让 agent 在实现具体功能的时候可以参考它的实现。👈 这么做更符合 skill spec 的规范
- 模版需要人为维护,我们的目的是帮助业务方更好得向 AGENT 描述需求,当然,这些模版的维护者往往是业务侧的开发者们。这个模板的设计符合 Codex SKILL spec,让 GPT 可以把它作为 SKILL 来理解我们业务侧的需求:
- AGENT 运行时:
- 这里的运行时指的并不是实际上执行代码的运行时,而是 agent 在执行 DAG flow 的运行时。
- Bee 在提交之后会固化成一份
task.json存在于当前用户的 workspace 中,这份文件由 metadata.json / config.toml 结合而成,用来描述整个 DAG flow 的运行时状态,DAG 在运行时会持续更新这份task.json,把它从 workspace 中映射到前端的展示层4。 - 至于运行时的 tape 存储,我继续复用 topic 的 tape 结构,每个 DAG Node 抽象为一个 Turn (🚧 这里会有坑,先埋个伏笔,读者朋友们可以先想一想), agent 通过 SKILL.md 和 BDD 的约束 (*.features)执行 DAG Node ,如果用户发现这个 Node 的产出不符合预期,用户可以通过调整 SKILL.md 来继续调试此 DAG Node 的行为。
- 在 DAG flow 全部完成之后,整个结构在 tape 的视角下,就又固化成了: topic_initial -> entries -> topic_finalized 。bee 的全部执行过程依旧可以通过 entry index 追溯,chat / bee 可以共用这些 topic memory 。在 chat 模式下,agent 可以很「智能」的知道你之前通过某个任务完成了某件事,得到了什么结果;在 bee 的模式下,agent 也可以自然的使用之前归纳总结过的某些 topic Q&A。
- 执行器:
- 对于一些 workload 比较高的,或者需要使用 Cron 的场景,我依旧复用了现有的 k8s 的基础设施 (通过 skill ),这会大大简化我们对于
bee本身的设计,而把可扩展性/资源控制/运行时安全/审计这些头痛的东西「外包」出去了。毕竟,专业的事情交给专业的人去做就可以了。我们通过 kubectl 也可以很方便的管理每个 pod 的状态。这个应该做过 k8s 二次开发的,懂的都懂了 XD。 - 如果之前没有还没有内部相关的基础设施,但是已经有了 Kubernetes Cluster , 那么我推荐下引入 Argo Workflow 的 operator 作为执行器的实现:
- Argo Workflow 作为一个云原生的 Operator ,天然支持 DAG ,可以很自然的对齐我们关于 DAG 的设计
- 可以自己根据具体业务场景定制化 Argo Workflow 的一些插件
- 依托于 Argo ,本身就是 CNCF 的 Graduated 项目
- 当然,为了管控相关的权限,我把这些 bee workload 放在了几个特定的 Namespace 里面,并且用 SA 限制了他们的可见范围,为他们打上了 topic id 的 label 。
- 对于一些 workload 比较高的,或者需要使用 Cron 的场景,我依旧复用了现有的 k8s 的基础设施 (通过 skill ),这会大大简化我们对于
交互上借着某个真实的案例说明下:
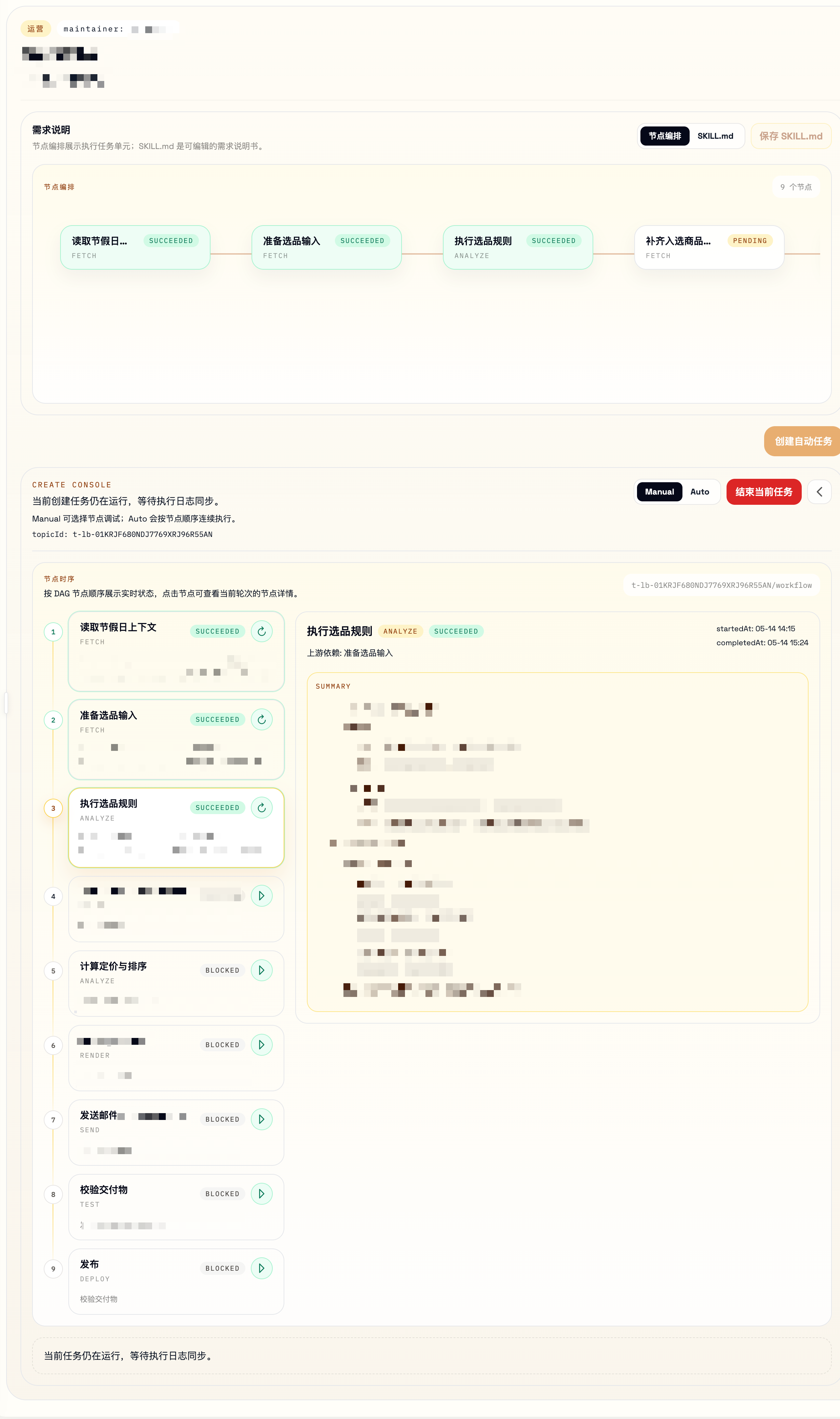
我们可以看到,针对一个具体的业务需求,我们把它拆成了几个有明确上下游依赖的需求,有点像我们平常开发过程,但是对于 agent 来说,它比我能力强的多,实现速度也快的多,为了让作为人类的我跟上它的节奏,方便二次验收它的工作成果,我只能让它尽可能「慢」一点,给我多一点 Review 的时间 ,也让我更有点参与感,别做完了一个需求,连自己到底干了什么都不知道 。所以,我还是把整个需求拆成了多个工作节点(里程碑),这些节点可以根据 SKILL.md 的改动被反复 trigger 以调试和对齐我们和 agent 的认知一致性。
关于这里的 SKILL.md ,我们维护了一个公用的 bee 模板 git 仓库2,把它作为一个文件服务器向 agent 暴露服务,作为 Source of Truth ,bee 模板初始加载的服务就来自于这个 git 仓库,但是,做过开发和产品的同学可能知道,业务的需求会一直摇摆不定,所以,我们也用 workspace (我为了偷懒,在写 chat 的时候就已经实现了,没想到这里被用起来了)的方式来支持对每个 bee 来进行特定的行为更改,workspace 是一个暂时的工作空间,生命周期绑定在 topic 上,topic 一旦被 finalized ,我们就会把 rw 权限都移除 (bee 本身就是 topic , 所以这里就可以被直接复用),在当前用户 workspace 达到配置上限时,移除当前用户创建时间最早的 workspace 。
这里的很多 DAG Node 其实都调用了很深的 skill chain , 这里我们可以参考很多微服务时期 RPC 对于最终一致性 (Eventual consistency) 最佳实践的做法。比如怎么对一个 SKILL 的调用做幂等,怎么回滚状态等等。
在发布流程,我们接入了 Argo Workflow ,agent 会负责根据自己写好的 workspace 的代码,来编写发布脚本 (这里是 Argo Workflow YAML Template, 天知道之前我为了调 YAML 的缩进和各种格式问题,近视加深了多少度,有 agent 实在太好了 🥹 ),然后用内置的 kubectl 工具发布上线。这里得说一下,因为我的 agent runtime 是基于 pi 和 bun 的,所以,这里使用了 bun / typescript 的技术栈 👈 这个需要在额外的 deploy skill 里面做说明。
对于我们现在人类能接受的开发流程,其实到这里还没有结束,因为我们发上去的代码很容易因为线上环境 ( Kubernetes Cluster) 上奇奇怪怪的配置导致运行失败,我之前的做法是把错误日志贴到 Codex , 让他帮我分析,然后由我去操作修改 Namespace 里面的配置。后来我一想,我的 runtime 不就是 GPT-5.4 ,为什么不让它自己分析自己解决呢,反正我都限制了权限了。于是,我创建了一个 Debug DAG Workflow Template,我就可以在部署完成之后串上另外一个 DAG workflow 了。再一想,这不就是是在 chat 里面对 topic 的引用 吗 ?我们平时 debug 的时候也需要回忆开发时发生了什么,再结合报错日志排查,才能让 debug 过程变快变稳,反而,大多数开发者都做不到这个(包括我自己)。但是借助 tape 的实现,我们可以再次唤起那时候的记忆。 (通过 topic range search !)
伏笔消除
过于复杂的 DAG Node Turn
虽然,我们通过人为拆分的方式,把一个具体的业务需求拆成了多个 DAG Node 来描述,但是,还是无法避免单个 DAG Node Turn 在运行时膨胀出超大的 Context Window,然后在这个 Context Window 中执行 toolcall 的时候因为一些奇怪的问题失败了,从而导致整个 Turn 需要重试。那么针对这种情况,是否说明 DAG 的设计出现了问题呢 ? 不是的,如果我们想一下真实业务开发的时候,碰到一个大迭代应该怎么做 ?当然是拆分成多个迭代节点(milestone)然后摸鱼啊啊。 那么映射到 tape 上也一样,我们可以在 bee 的 dag flow 上抽象出 DAG Anchor 来做一些记录来让 agent 可以知道自己之前干过什么,接下来该干什么 (这也在 spec 上符合 tape anchor 做状态记录的通用语意):
DAG Anchor
DAG Anchor 是一种在 DAG 中专用的 Anchor , 相比于 handoff 产生的 brain_overload anchor , dag anchor 的产生更加频繁,它记录了调用了每个系统RPC/API/CLI 之后的结果:
topic_init
-> bee_task_init // 整个 Bee task / DAG 实例摘要,只写一次
-> bee_node_init // 当前要执行的 DAG node 开始
-> entries... // 这轮 agent thinking/tool/message/run entries
-> bee_node_fin // 当前 node 结束,总结本 node 结论
-> bee_dag_checkpoint // 汇总整个 DAG 当前进度
-> bee_node_init // 下一个 node 开始
-> entries...
-> bee_node_fin
-> bee_dag_checkpoint
...
-> bee_task_fin // 整个 Bee task 结束
-> topic_end
DAG Anchor 牺牲了一些存储(tape storage)上的冗余,来换取了更清晰(对人类友好的同时,同时对 AGENT 也更友好)的思考和重新过程。如果我们在某个 API 上超时导致 DAG Node 运行失败,这时候 AGENT 在重试的时候就知道了上个 turn 的执行情况和各个外部调用的结果,它就可以评估是否需要重试,从哪里开始重试。
写在后面
bee 其实不是我第一个我对于 topic 的扩展实现,第一个扩展是为了扩充我们对于 agentic-rag skill (一种由 agent 自启发的 RAG 实现)的想象。因为我们的知识库数据基本全部来自于代码仓库,但是有时候还是需要一些外部的文档 wiki 记录来丰富知识库数据,这时候就需要一个类似 importer 的东西导入 wiki 并且映射到 RAG 的向量空间。
这时候我就想到重用 topic 的设计针对外部数据源的数据进行多轮 turn 的迭代,然后入库。但是这里的设计还是倾向于对 chat 的延伸,每轮 turn 都会有 human-in-loop 的反馈。
这也是为什么后来引入 bee 的时候需要对代码进行大量的重写,因为涉及到了消息架构层(ws)的改动之后,就发现之前的 AI Slop 代码有很多的坏味道。
抛开这个不谈,我开始对 topic 有了更多的想象。
或许人生本来就是由大大小小的 topic 组成的吧,毫无新意,千篇一律。
也许也不是,我们并不需要定义每个 DAG 节点的产出是否符合期望,我甚至都不知道我应该对自己有怎样的期望,每个人都有每个人自己的生活和想法吧。
JUST HAVE FUN , AND BREAK SOMETHING.
-
我还是挺感谢公司给的 机会 和 token 去让我探索从零开始手搓 agent 的,踩了很多坑,有很多感悟,也有了很多实质性的收获 ♥️ ↩︎
-
用 Git 作为模板仓库是有更多考虑在的: 因为可能会涉及到实际的线上业务调整,虽然我们可能没有 blame 文化,但是我们还是要进行版本管理,以追溯每个版本产生的变化,以及支持审计方面的需求。Git 天然就满足了我们的需求,减少了其它工具的维护负担。 ↩︎
-
DAG (Directed Acyclic Graph): 借用有向无环图的概念来描述一个实际的业务需求。这种数据结构在用来描述「调度」时会被经常提及。 ↩︎
-
这里使用
task.json这种 workspace 里的临时存储(甚至还是一份 JSON 文件),一方面是我觉得我已经有 tape storage 来帮我存储 dag anchor 的 state 了没必要再引入更复杂的实现;另一方面是 JSON 的记录形式对 debug 来说还挺方便的 (其实就是我懒) ↩︎
Author scnace
LastMod 2026-05-19