tape x topic: 我对智能体上下文的组织方式
Contents
想借这篇文章,记录一下我这段时间对 agent 和上下文组织方式的理解。
Hello Tape
我是偶然认识 Tape 的。那几天我对全是 🦞 的信息流已经有点疲劳,本来以为它又是一个新包装出来的概念,结果顺着 tape 读下去,反而被它的抽象吸引住了。
Tape 用“纸带”来描述 agent 的 context window:每个关键时刻都像纸带上的一个孔,平时可以折叠,需要回溯时再展开。历史没有消失,也不会被凭空改写。
在它之前,我觉得能参考的 agent context 设计,主要还是几篇头部团队的文章。
- AI代理的上下文工程:构建Manus的经验教训:Manus 给我的启发主要有三点。第一,用文件系统而不是单纯靠压缩摘要去承接历史;第二,错误也是历史的一部分,不该被抹掉;第三,通过「Action -> Document」让 agent 的行为更可追踪。我对 MCP 和 MCP-like 方案一直有点保留:工具集一旦过大,agent 很难长期稳定地把注意力放在正确的位置上,成本和误判都会跟着上来。
- AMP: Context Engineering:AMP 更像是面向 Coding Agent 的工程化方案。它把复杂的 tool call 收敛成
read / write / edit / bash四个基本动作,再通过 sub-agent 和 handoff 控制上下文膨胀。
相比之下,AMP 更像是对 Coding Agent 的优化,而 Manus 提出的设计更能引出我对 General Agent 的思考。
Manus 的方案也让我一直在想几个问题:
- 「Document 的存储介质」为什么一定要是文件系统?如果企业已经有数据库或对象存储,能不能直接复用?
- Document 的并发控制该怎么设计?如果相似的 Action 产出不同的 Document,会不会反过来干扰 agent 的判断?
- Action 和 Document 之间,到底应该抽象成什么样的范式?
也是因为这些问题,我看到 Tape 时会觉得它的设计会更加自然。
Tape as Spec
Tape 本身不是一套具体实现,更像是一份关于 agent 系统该怎么组织上下文的设计说明。如果你想用它设计出来的智能体可以长成什么样,可以试试 bub。这篇文章还是聚焦在 Tape 的设计本身。
合理的抽象
我一直相信,好抽象不是“造概念”,而是不断贴近真实场景和现实规律。Tape 的设计很符合这个标准。
- Tape 对应一个真实的 LLM Session。每个 session 自诞生起就有自己的一条纸带,历史只能向前累积。
- Entry 是最小单元,记录一次真实交互:用户输入、模型回答、工具调用都算。Entry 不应该被篡改或删除。agent 得出错误结论时,正确做法不是回头改历史,而是追加一条“这里错了、后来怎么修正”的新 entry。
- Anchor 是特殊的 Entry,用来标记值得回溯的节点。它可以是“错题本”,也可以是“一个值得保留的好想法”。Anchor 本质上是对若干 entries 的提炼,所以扩展空间很大。
- View 是一组 Entry 的集合。你可以把它理解成一个项目、一段任务周期,或者任何需要被回顾的主题窗口。项目资料、讨论分歧、关键里程碑都能落在同一个 view 里。
- 当单个 session 也撑不住上下文长度时,Tape 通过
handoff解决问题:先产出一个带前序状态的 Anchor,再把窗口往后推进。原始信息仍然保留,只是默认不再每次都展开。
Tape 给的抽象不多,但都很准。也正因为它足够克制,实现层才有足够的发挥空间。
对基础设施足够友好
Tape 的另一个优点,是它不强迫你接受某一种固定基础设施。抽象稳定之后,存储层就可以按场景替换:
- 单机场景可以像 Manus 一样,用本地 JSONL 持久化 entries 和 anchors。
- 分布式场景可以把 entries 和 anchors 放进数据库或对象存储里,方便扩展和横向伸缩。
- 如果场景强调“回忆”,也可以接入向量数据库来承担召回能力。
这些都不是新问题,业界已经有很多成熟实现。对企业来说,理想做法往往不是再造一套新设施,而是复用已有的数据基础设施。
甚至连可观测性平台也可以接进来。比如在 entry 上记录 token 消耗,把 Tape 变成一套 agent 的“记账系统”。
Topic
Topic 是我基于 Tape View 衍生出来的一个高层抽象,对应的是我自己的业务场景:企业知识库问答。
公司最近在推进 AI 知识库建设,但真实问题往往不是“这段知识怎么解释”,而是“这个业务问题落在哪块系统、应该去哪里查、怎么查更高效”。如果只让开发自己用 skill 或 Coding Agent,还解决不了跨角色协作的问题。产品、测试、运营带着业务话题来问时,背后对应的通常是一段复杂的代码和流程。
所以我想做的 agent,更像一个“面向代码库的客服”:它需要理解业务话题,知道该去哪块系统里找线索,也要知道怎么判断自己有没有找对。
这类场景对上下文组织有几个明确要求:
- 用户的话题需要可回溯、可复用。很多问题不会只出现一次,后续对话应该能继承之前积累的经验。
- 系统要有可观测性,至少能看清 token 开销和行为链路。
- 在企业环境里,还要兼顾数据安全和实现成本。
也是基于这些考虑,我最后选了 Tape 作为整体设计的底层约束。
但 Tape 当时并没有 Topic 这一层抽象(感谢摆锤哥哥认可我对 topic 的设想 🥰)。于是我开始基于 Entry / Anchor / View 填补了这个空白。
Topic 的基本实现
我的想法其实很直接:在话题开始时写入 topic_initial,在用户明确结束时写入 topic_finalized。这两个 Anchor 之间的 entries 和 anchors,就构成一个 topic。
这样一来,底层仍然是 Tape,但对用户暴露出来的可以是更贴近业务直觉的概念,比如 ChatBot 常见的「Topics」列表。
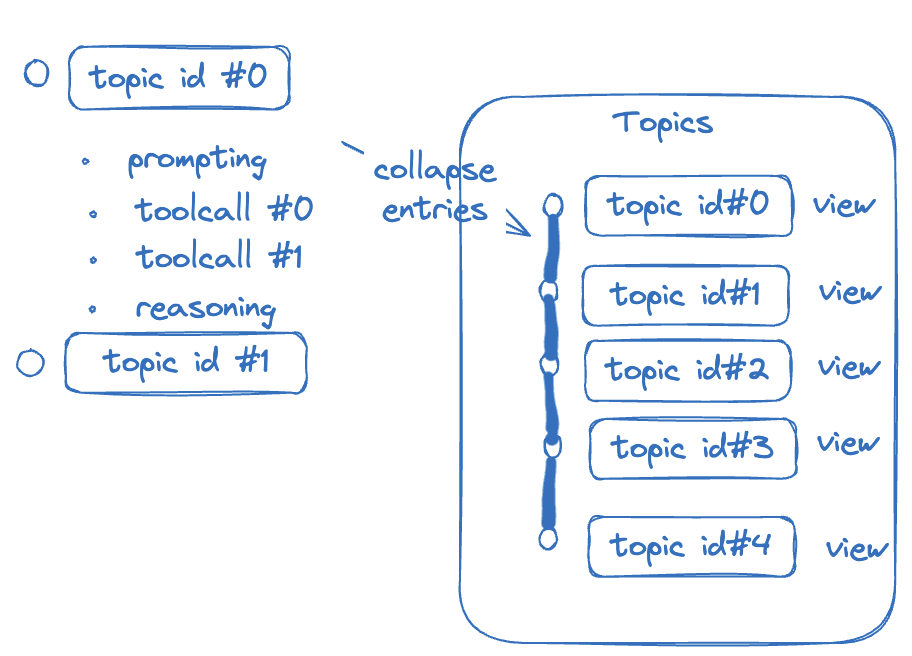
存储层上,我只是在 Tape 原本的 entry 和 anchor 之上补了一层 topic 元数据:topic_initial_index、topic_finalized_index、topic summary,以及 owner、timestamp 等业务字段。这里的 index 我更倾向用自增 seq,因为后续做 range search、统计 entry 数量都会更直接。
给 Topic 加上一层生命周期 hooks
为了让它更适合真实业务,我又加了一层 hooks,把 topic_initial 和 topic_finalized 变成 topic 生命周期的起点和终点。围绕它们,可以扩展出:
pre_topic_initial_hookspost_topic_initial_hookspre_topic_finalized_hookspost_topic_finalized_hooks
有了这层机制,topic 就能自然长出不同形态。
正常主题(Common Topic)
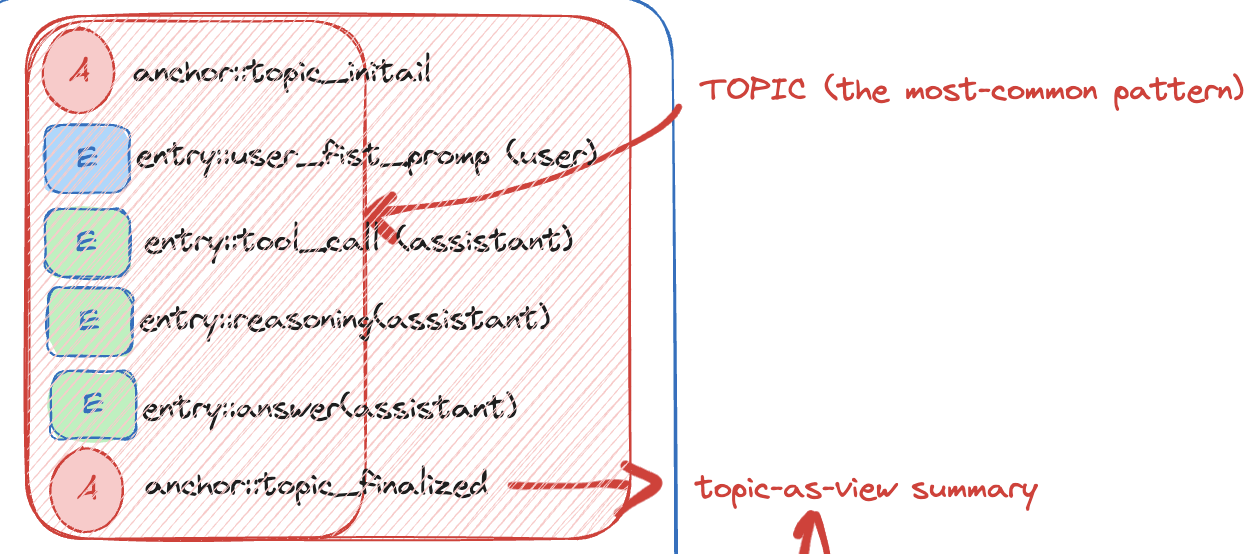
这是最标准的一条生命周期:开始、交互、结束,完整而清晰。
需要回忆的主题(Memory-able Topic)

在 post_topic_initial 之后插入 recall 流程:先根据当前需求去历史 topic summary 里检索相关主题,再把召回结果写成一个 recall_anchor 带回当前上下文。它占用的上下文很小,但需要时仍然能顺着 index 范围继续追溯原始 entries。
没有正常结束的主题(Aborted Topic)
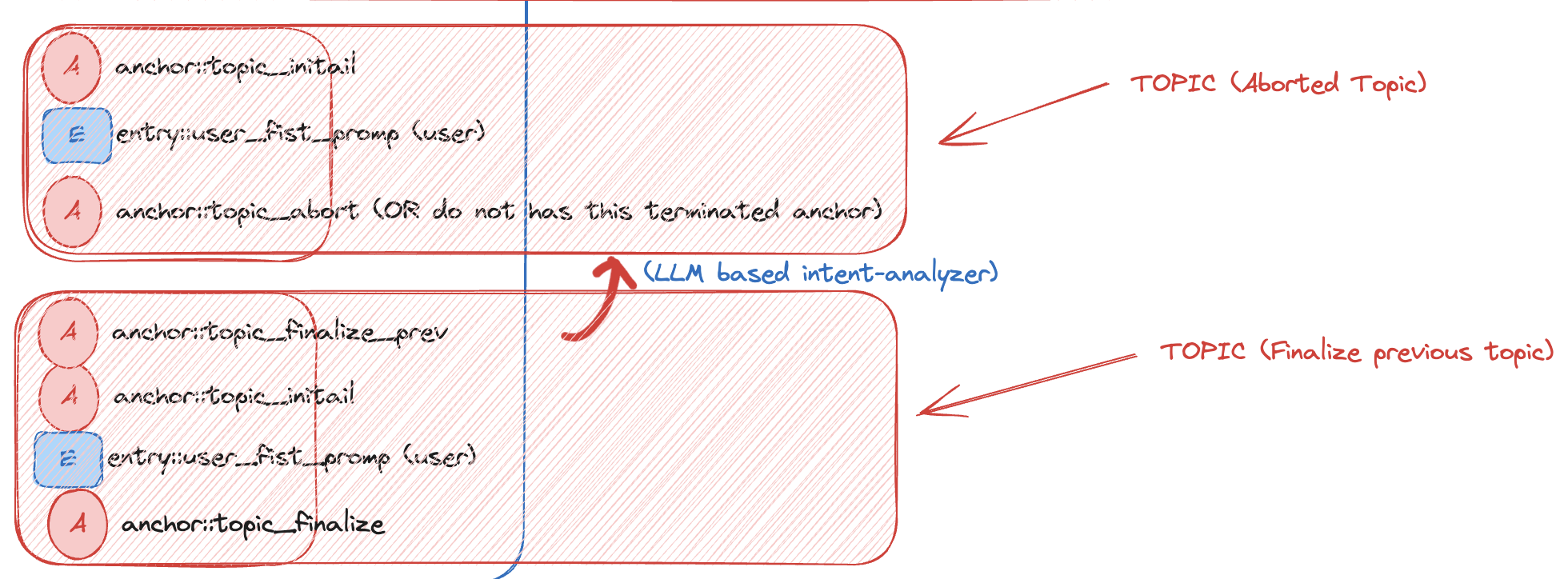
真实用户不会总按流程出牌。有时上一个 topic 还没结束,新的 topic 已经开始了。为避免上下文错乱,我在 pre_topic_initial 阶段加了一个 topic_finalize_prev:开启新话题前,先检查上一个 topic 是否已经结束;如果没有,就补一条 topic_finalized。
超长主题(Extra-Large Topic)
这一类不用额外 hooks,但仍然要用 Tape 原本的 handoff。当单个 topic 超出上下文窗口时,可以插入一个中断 Anchor,我暂时把它叫做 brain_overload。它记录中断位置和一段 summary,这样一个 topic 就会被切成多个可回放的段落。
未完待续。按业务需求继续扩展 hooks,本质上仍然是在同一套组织方式上做演化。
我对 Topic 的几个后续提案
- Share-able Topic:允许 topic 作为一个可分享的业务单元,被别的同事或别的业务线引用。这样大家既能看摘要,也能沿着 topic 继续追到细节。类似 XuanWo 的 xurl,以后甚至可以直接问:「根据 @scnace 的开放知识库,这个问题该怎么处理?」
- Fact Topic:在
post_topic_finalize阶段接入 RAG,把 topic 中沉淀出来的业务结论转成 contributor 维度的 metadata。 - Topic Cost:按 topic 统计 token 花费,把成本也纳入可追踪范围。
Topic 作为对 Tape View 的进一步抽象,让我更确信 Tape 不只是一个漂亮概念,而是真的能落进业务系统里。
Memory
在这种上下文组织方式下,“记忆”会变得很自然。
相比某些 🦞 的外挂 memory 方案,这种做法不需要再额外维护一套割裂的系统:不用单独再起一层数据库,也不用为“记忆模块”额外付出一层系统复杂度。
在我的理解里,Tape 不需要额外设计一个 memory 子系统。Entry 和 Anchor 本身就提供了“沿时间漫游”的能力,这就是记忆。它不是外挂,而是 agent 的基础能力。
Tape to Any-Agent
Tape 是一套设计语言,不是某个固定产品。它可以被拉向不同的垂直场景:比如 bub 更专注于群聊场景的群像智能体,而我更关心企业知识库问答。
如果继续往前走,我希望 Tape 最终能变成一个足够稳定的内核:它既能承接不同场景的 agent,也能在运行中逐步完成自我抽象和自我迭代。某种意义上,它很像 agent 世界里的“百变怪”。
Credits
Author scnace
LastMod 2026-03-27